Persisting nodes in Laravel
In this series, we’ve studied various node clusters and how we can search them, infer new data from them and transform them using visitors. However, we still don’t know when to use them and how to store them.
Not everything can or should be modelled as a cluster of nodes. In this episode, I’ll provide concrete use-cases where using nodes should be considered or avoided.
In addition to that, we’ll also see a different way of storing our nodes for each example we’ll examine.
Since my blog is mostly focused on the Laravel framework, we’ll use Eloquent models when storing data in a database.
Compiling languages
Let’s start by getting languages out of the way.
Throughout this series, our running example — the calculator that remembers — has been a language.
Languages are the perfect use-cases for nodes since every language is at some point parsed into what we call an Abstract Syntax Tree (AST). Once we have an AST version of a program, we can create visitors that evaluate it directly or create more optimised compilers for it.
This applies to programming languages but also markup languages like HTML whose AST is most commonly known as the DOM.
We’ll talk more about this in another series dedicated to creating your own domain-specific language (DSL).
Using a language like our calculator was helpful to study a wide range of concepts regarding nodes and visitors. But let’s face it, we don’t need to create languages every day. In the rest of this article, we’ll forget about our calculator and study real-life example that could benefit from nodes and visitors.
Developing games
Another tech sector that benefits a lot from this pattern is artificial intelligence (AI) and game development.
For example, when developing an AI for a game of chess, you can model a snapshot of the current game as a node whose children are snapshots of the game after each possible move.
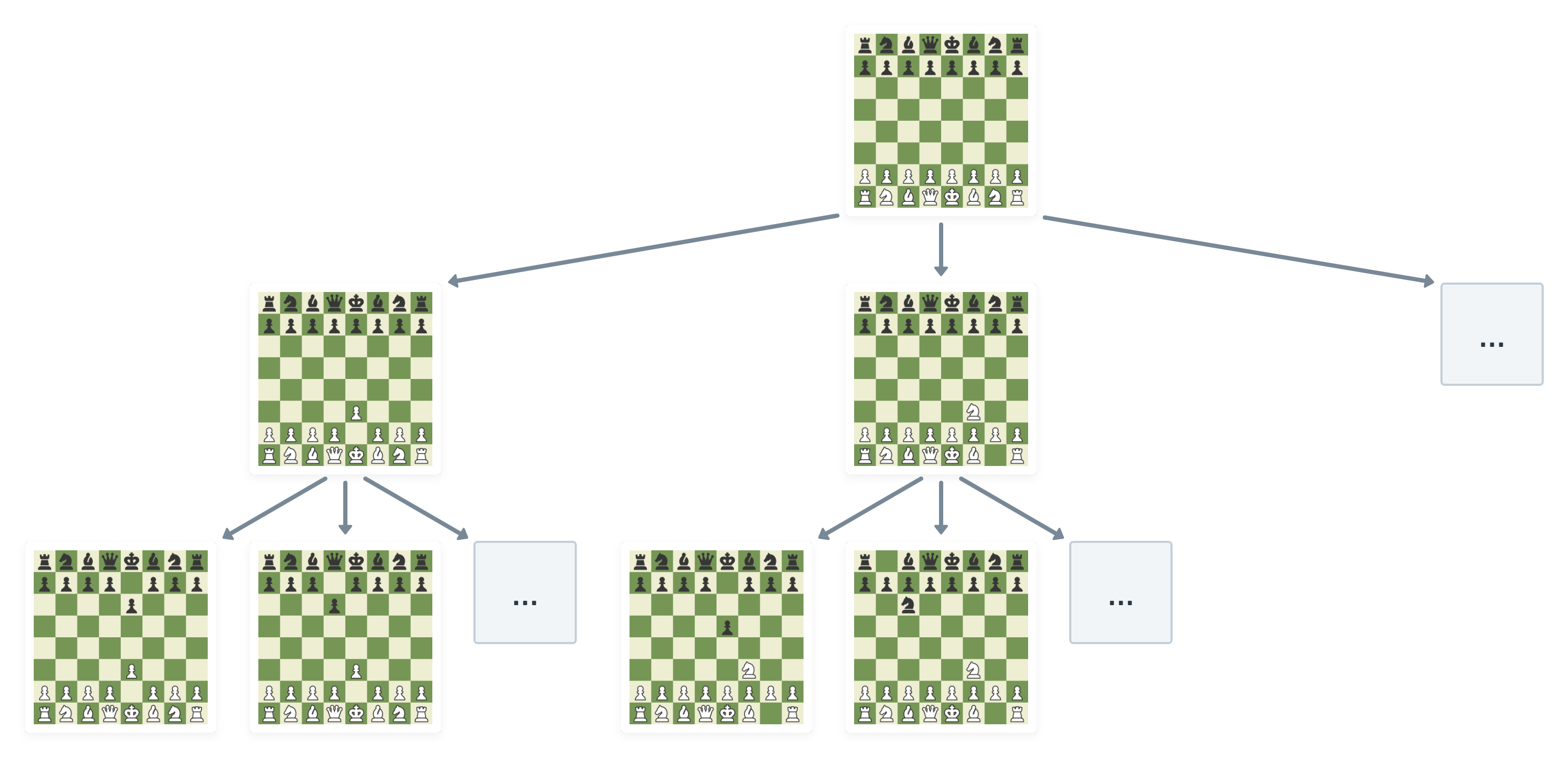
As we’ve seen in the breadth-first search episode, nodes can also help when handling maps, movements and path findings in games.
In short, a lot of the magic that happens behind the scene of game development benefits from this pattern.
However, if you’re reading this blog, chances are you’re more likely going to apply what we’ve learned to web applications than games. Thus, that’s what we will focus on for the rest of this article.
The use-case matrix
Okay, aside from languages, AI and games, what can we use nodes for in web applications?
To find the answer to that question, let’s break down node clusters into 4 categories by using 2 factors.
- Depth. We’ll distinguish node clusters that are only one level deep from the ones that can have deeper levels. You might be wondering what is the point of nodes that are only one level deep — since that means a cluster with no children — but you’ll see there’s even a use case for that.
-
Number of different node types. We’ll distinguish node clusters that are only made of the same type of node from the ones that have at least two. For instance, our calculator example had 7 different node types:
Number,Add,Subtract,Minus,Assign,GetandCalculator.
And so we end up with the following 2x2 matrix.

The very first cell has been crossed since there is not much one can do with node clusters made of only one type of node that has no children. What you’re left with is just an object or a list of objects.
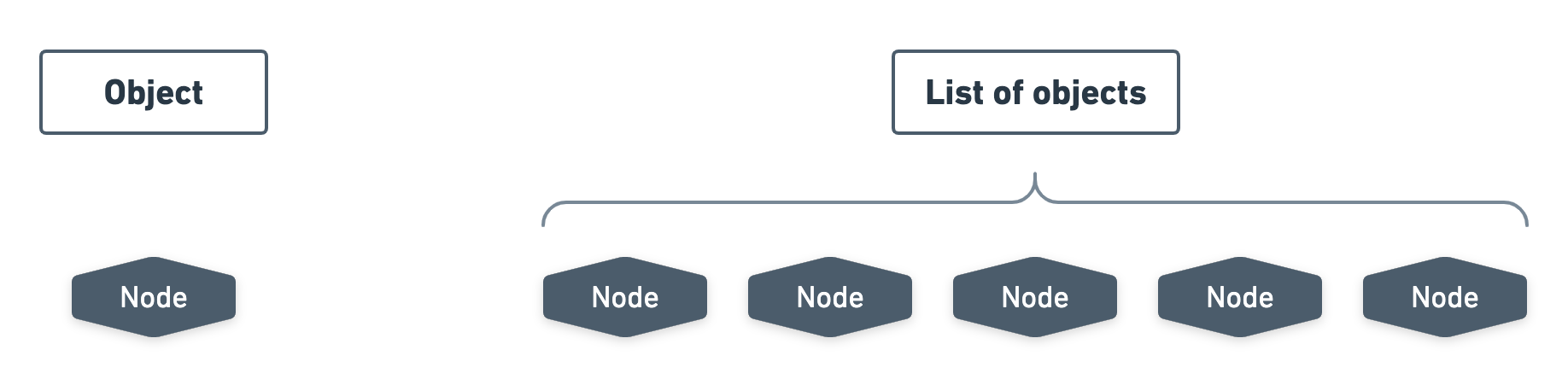
The next cells marked as 1, 2 and 3 make up the three categories of use cases we’re going to study in the rest of this article.
Polymorphic relationships

Okay, let’s start with our first category of clusters: multiple node types but without children.
It’s easy to see the benefits of visitors when applied to nodes that may have many nested children but visitors are also very good at handling polymorphism.
Imagine you’re creating a Uber-like application where your users can have one of the following profile: Admin, Driver or Rider. Say you decide to implement this using polymorphism. That is, a user has a profile_type and profile_id referencing a row in one of these profile tables.
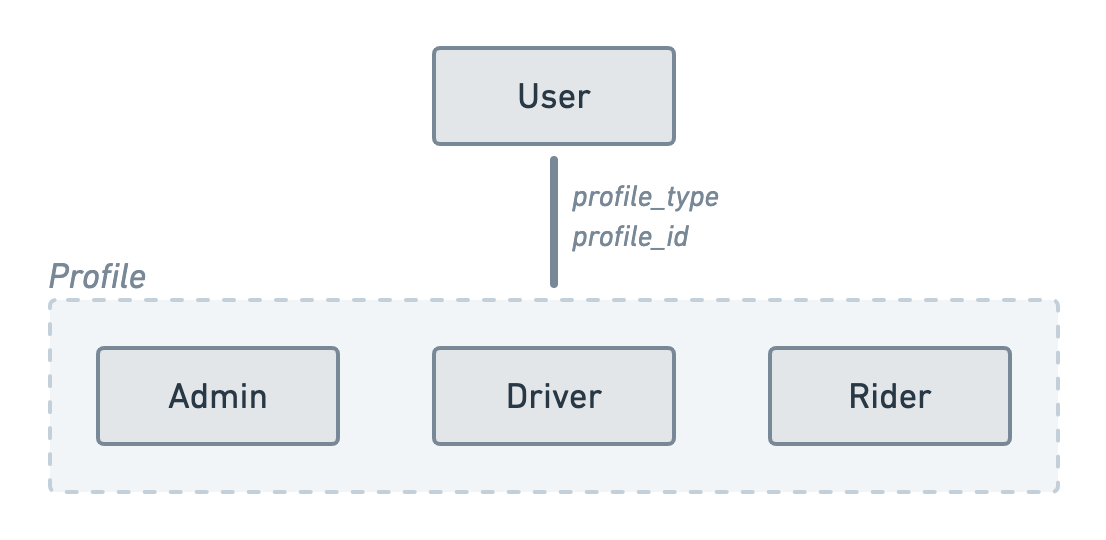
class User extends Authenticatable
{
public function profile()
{
return $this->morphTo();
}
}
Now, imagine you have lots of user operations that depend on the user’s profile. One way to achieve this would be to create a Profile interface defining all profile-specific operations for our users. Our Admin, Driver and Rider models would then need to implement all methods of this interface.
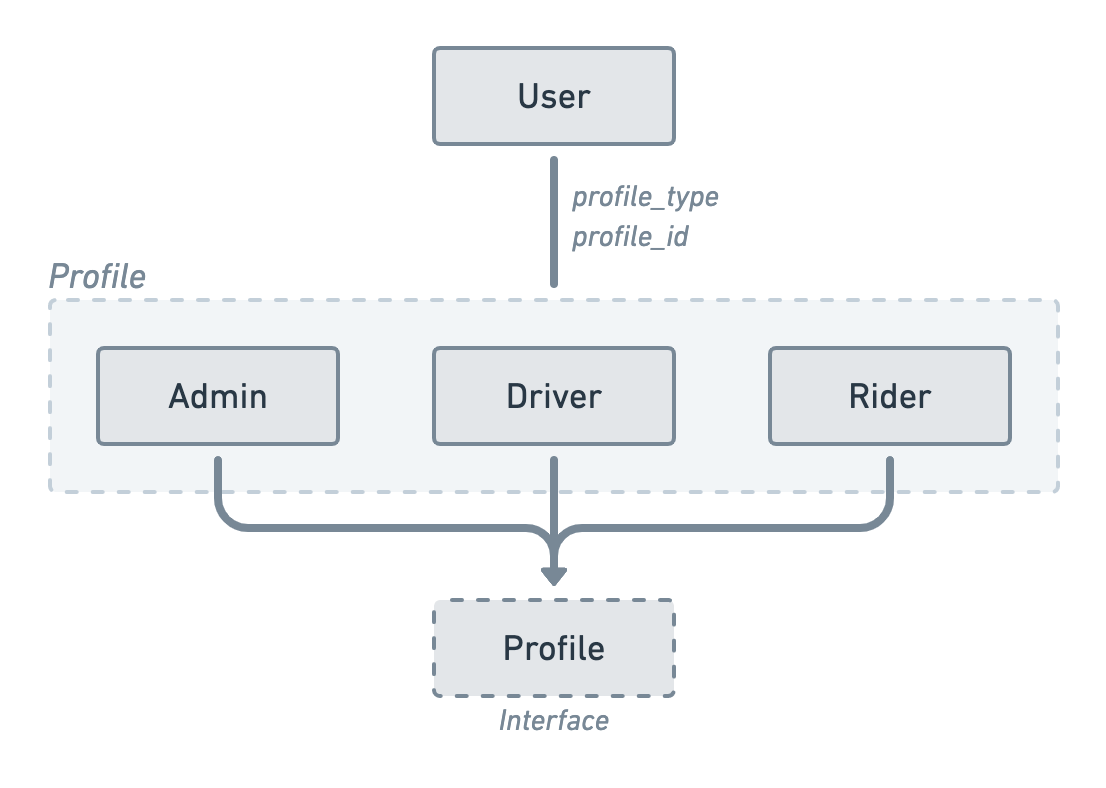
There is nothing wrong at all with this approach but if you start having more and more profile-specific operations, your models will end up being huge dictionaries of operations mixed with their own data representation.
As we’ve seen in this series, visitors are great at decoupling data and operations so why not use them here too?
We’ll create a ProfileVisitor abstract class and a ProfileVisitable interface for our nodes. Whilst our visitors will only be asked to visit the Admin, Driver and Rider nodes, we will also make the User class implement the ProfileVisitable interface such that it immediately delegates the accept call to its polymorphic profile.
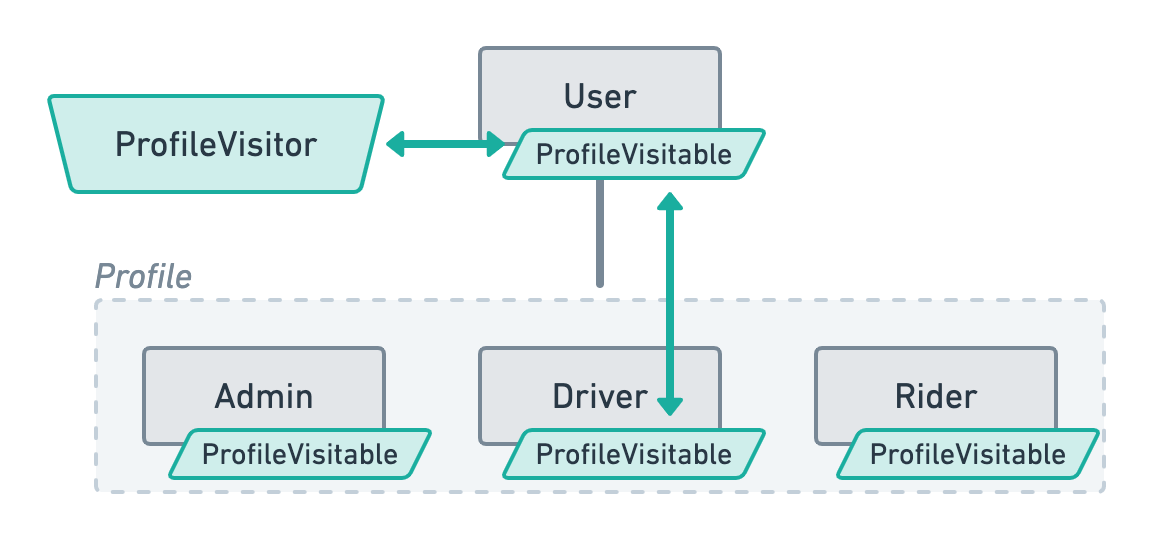
Regarding the implementation, there’s really nothing new here. We’re just applying what we’ve learned using Eloquent models as nodes.
interface ProfileVisitable
{
public function accept(ProfileVisitor $visitor);
}
abstract class ProfileVisitor
{
abstract public function visitAdmin(Admin $admin);
abstract public function visitDriver(Driver $driver);
abstract public function visitRider(Rider $rider);
}
class User extends Authenticatable implements ProfileVisitable
{
// ...
public function accept(ProfileVisitor $visitor)
{
return $this->profile->accept($visitor);
}
}
class Admin extends Model implements ProfileVisitable
{
public function accept(ProfileVisitor $visitor)
{
return $visitor->visitAdmin($this);
}
}
class Driver extends Model implements ProfileVisitable
{
public function accept(ProfileVisitor $visitor)
{
return $visitor->visitDriver($this);
}
}
class Rider extends Model implements ProfileVisitable
{
public function accept(ProfileVisitor $visitor)
{
return $visitor->visitRider($this);
}
}
And that’s it! Now, whenever we need to implement a user operation that depends on its profile, all we need to do is create a new ProfileVisitor and pass it to the user.
$user->accept(new GreetUserVisitor());
class GreetUserVisitor extends ProfileVisitor
{
public function visitAdmin(Admin $admin)
{
$numberOfSupportTickets = $admin->supportTickets()->count();
return "Morning! You have $numberOfSupportTickets support tickets ready for you.";
}
public function visitDriver(Driver $driver)
{
return 'Hi! Ready for your next customer?';
}
public function visitRider(Rider $rider)
{
return 'Welcome back! Where are you off to?';
}
}
Little disclaimer: Please bear in mind that there are many ways of handling polymorphic relationships — and many ways of persisting different user profiles. You shouldn’t default to modelling everything as nodes just for the sake of it but it’s a good technique to add to your belt should your use-case benefit from it.
Maintaining hierarchy

Let’s move on to our second category: nested node clusters composed of only one type of node.
This category typically applies to objects that define a hierarchy. An example of such a hierarchy could be a family tree. Each node represents a human being and their children represent, well, their children.
Even though our visitors would only need to visit one type of nodes, they are still useful to:
- Decouple operations from its data representation
- Handle recursive operations
For this example, we’ll examine a Reddit-like nested comment system. Users can comment on posts and reply to comments by adding a nested comment. We’ll model this nested relationship by adding a nullable parent_id column to the comments table that references its parent row if any.
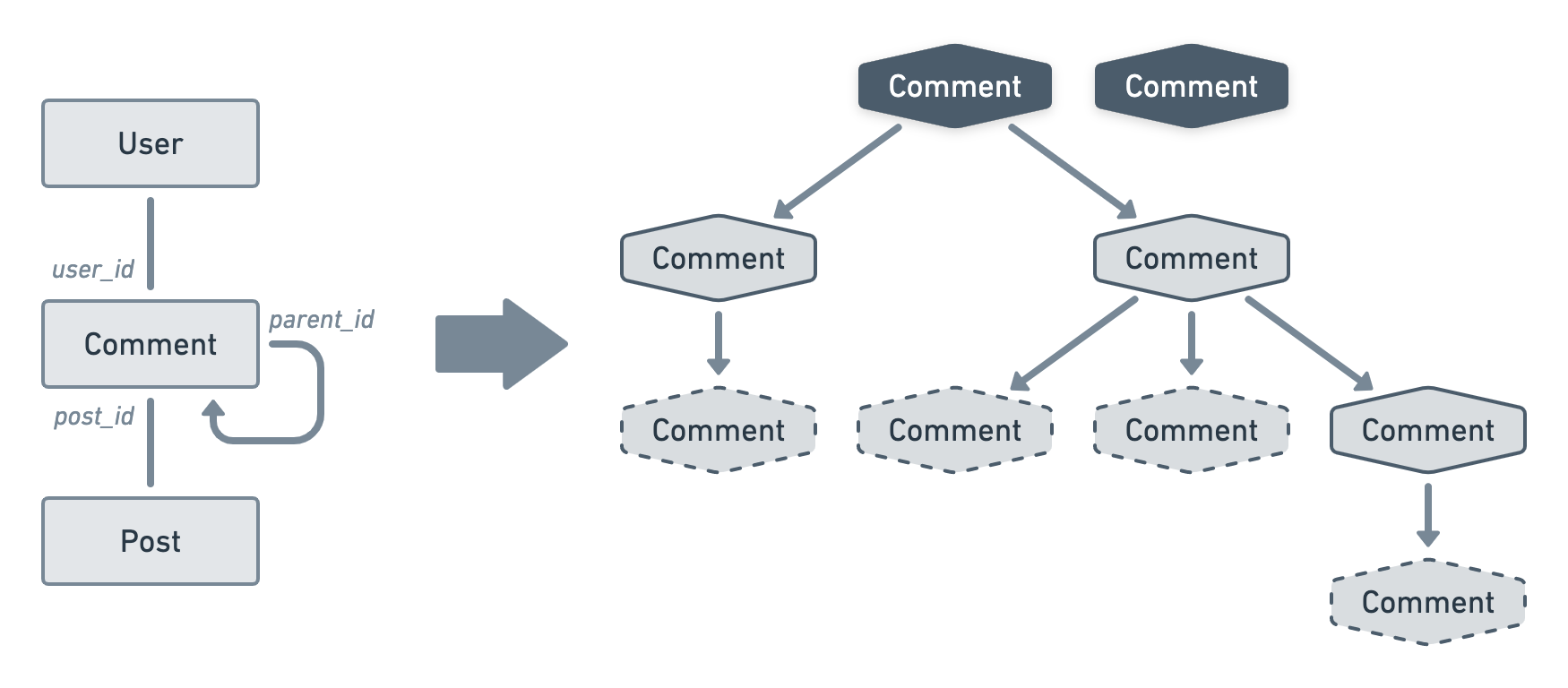
Note that we end up with a forest of trees since a post can have many "top-level" comments.
A quick note on performance
Storing the parent_id is a great way to normalise a tree — and recursion in general — but can easily make your application less performant if we’re not careful. This is because we will need to query the database at every single node in the tree to fetch their children. That being said, there are ways to make recursive tables more efficient.
If you’re using MySQL 8 and above, you can benefit from Common Table Expressions (CTE) to make a single nested query that fetches the entire tree at once. There is even a Laravel package for it.
Alternatively, you can structure your database table with additional "pointer" columns that need to be maintained after each database changes. Whilst this makes your database writes slightly less efficient, it again enables you to fetch an entire nested structure with only one database query. A very good implementation for this I used a while ago is the Baum Laravel package. Be careful though it looks like it’s no longer actively maintained. Nevertheless, I recommend reading the README of this repository to get a better understanding of what I mean by "pointer" columns.
Back to our nested comments
Alright, let’s implement the CommentVisitor abstract class and the CommentVisitable interface to apply to our Comment model. Nothing new here aside from the parent() and children() relationship methods that both use the parent_id column with different relationship classes.
interface CommentVisitable
{
public function accept(CommentVisitor $visitor);
}
abstract class CommentVisitor
{
abstract public function visitComment(Comment $comment);
}
class Comment extends Models implements CommentVisitable
{
public function user()
{
return $this->belongsTo(User::class);
}
public function post()
{
return $this->belongsTo(Post::class);
}
public function parent()
{
return $this->belongsTo(static::class, 'parent_id');
}
public function children()
{
return $this->hasMany(static::class, 'parent_id');
}
public function accepts(CommentVisitor $visitor)
{
return $visitor->visitComment($this);
}
}
Done! Now, let’s create a quick visitor for it. We’ll implement a visitor that returns a unique list of all users that wrote a comment within that tree — let’s call them "participants".
Note that you might also want to make the User and Posts models implement the CommentVisitable interface so that you can get the participants from all top-level comments at once.
class GetCommentParticipantsVisitor extends CommentVisitor
{
public function visitComment(Comment $comment)
{
// Get the comment's children.
return $comment->children
// Recursively fetch and flatten their unique participants.
->flatMap->accept($this)
// Add the current comment's author in the participants.
->merge([$comment->user])
// Ensure all participants are unique again via their `id` property.
->unique->id
// Ensure we don't get an associative array.
->values();
}
}
And that’s it! Now you can use that visitor like so:
$participantsOfTheThread = $comment->accept(new GetCommentParticipantsVisitor());
// Or, if the User and Post models are also CommentVisitable.
$participantsOfThePost = $post->accept(new GetCommentParticipantsVisitor());
$participantsOfAllMyComments = $user->accept(new GetCommentParticipantsVisitor());
The node cluster illusion

We’ve now reached the third category: a deeply nested cluster with more than one type of nodes. When a use-case fits into this category, chances are nodes and visitors are going to be a great way to tackle it.
Our previous calculator example fits this category perfectly by having 7 different node types and because the Add, Substract, Minus, Assign and Calculator nodes can have one or more children.
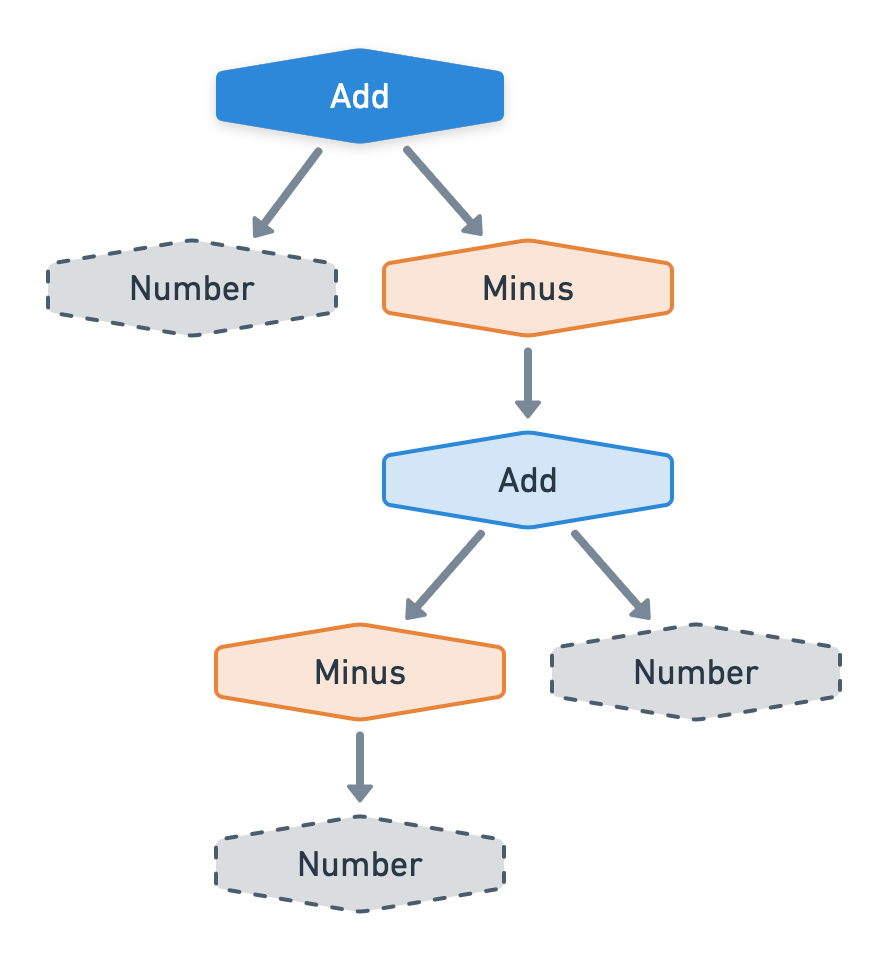
Now, before we examine an example of this category in detail, take a look at this node cluster.
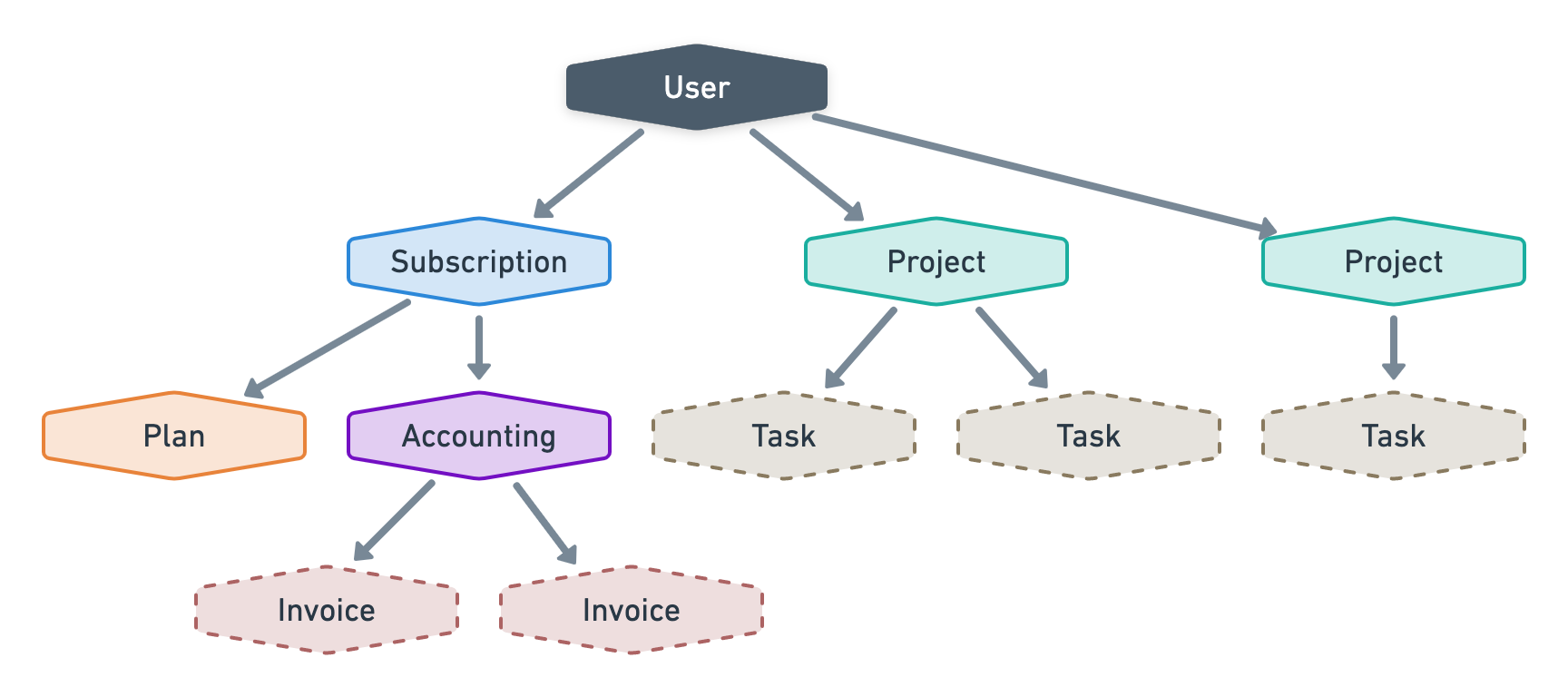
At first, it looks like the perfect use case for nodes and visitors. It has 7 different node types and its User, Subscription, Project and Accounting nodes can each have more than one child.
However, if you look closely, you’ll notice there is no recursion in this cluster. For example, the Subscription node cannot eventually have another Subscription node in its descendants. All we’ve done in this example is arrange a few objects types based on their relationships.
No recursion means you are probably trying to force the node and visitor pattern to a structure that probably doesn’t need it. There are of course exceptions since visitors are also great at handling polymorphism which is why I would consider this example to belong to the first category rather than the third one.
The key here is to be mindful of how many node types are repeating themselves as we go deeper into the cluster. If there is even just one recursive node type, then that’s all it takes to be in category 3. Take a look at this example below.
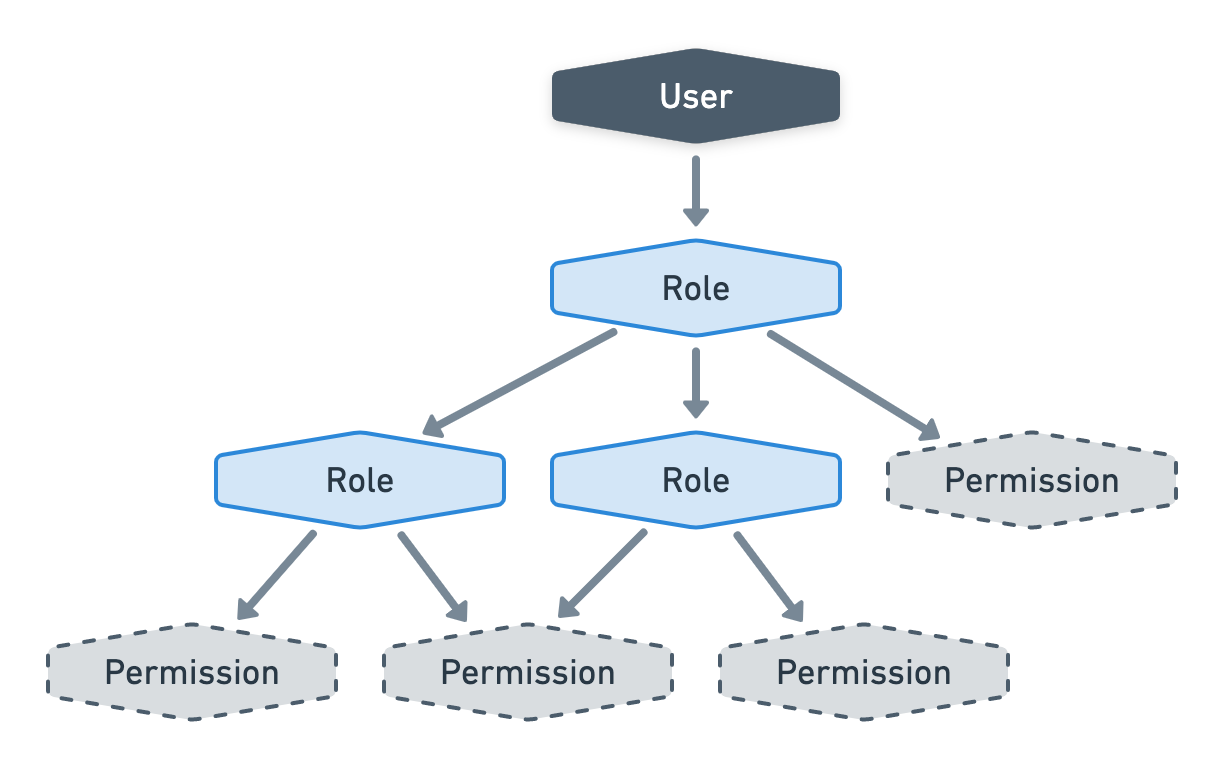
We’ve got a Permission node type that can only be a leaf has it has no children but we’ve also got a Role node type that makes the cluster recursive by having children that can be either of type Role or Permission. Also note that it is not a tree since it can have undirected circles.
Okay, you’ve been warned. Now, let’s examine an example that is both recursive and part of the third category.
A nested structure for Figma
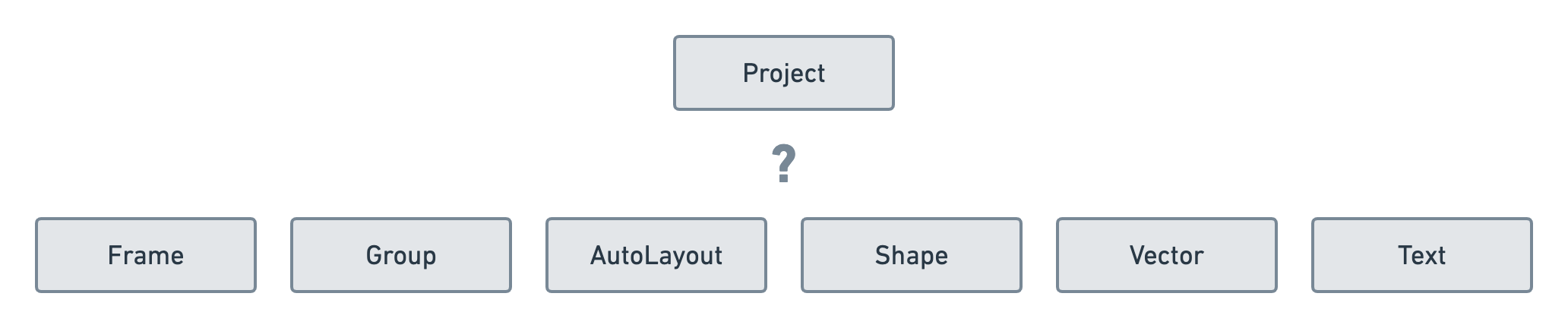
Imagine we’re implementing some sort of 2D vectorial design software like Figma. Here, we will focus on the data that end up structuring the design itself. For example, in Figma, you can have a Shape layer and a Text layer wrapped inside a Frame or Group layer.
For our simplified use-case we will only use the following node types:
- Frame. Groups many layers together and acts like an artboard.
- Group. Groups many layers together and acts like a folder.
- AutoLayout. Groups many layers together and acts like a CSS flex container.
- Shape. Predefined vector objects that can be configured via options.
- Vector. Custom vectorial objects in one layer.
- Text. A text layer with some content and typography options.
Here is an example of what these node types look like in Figma and how they are structured together.
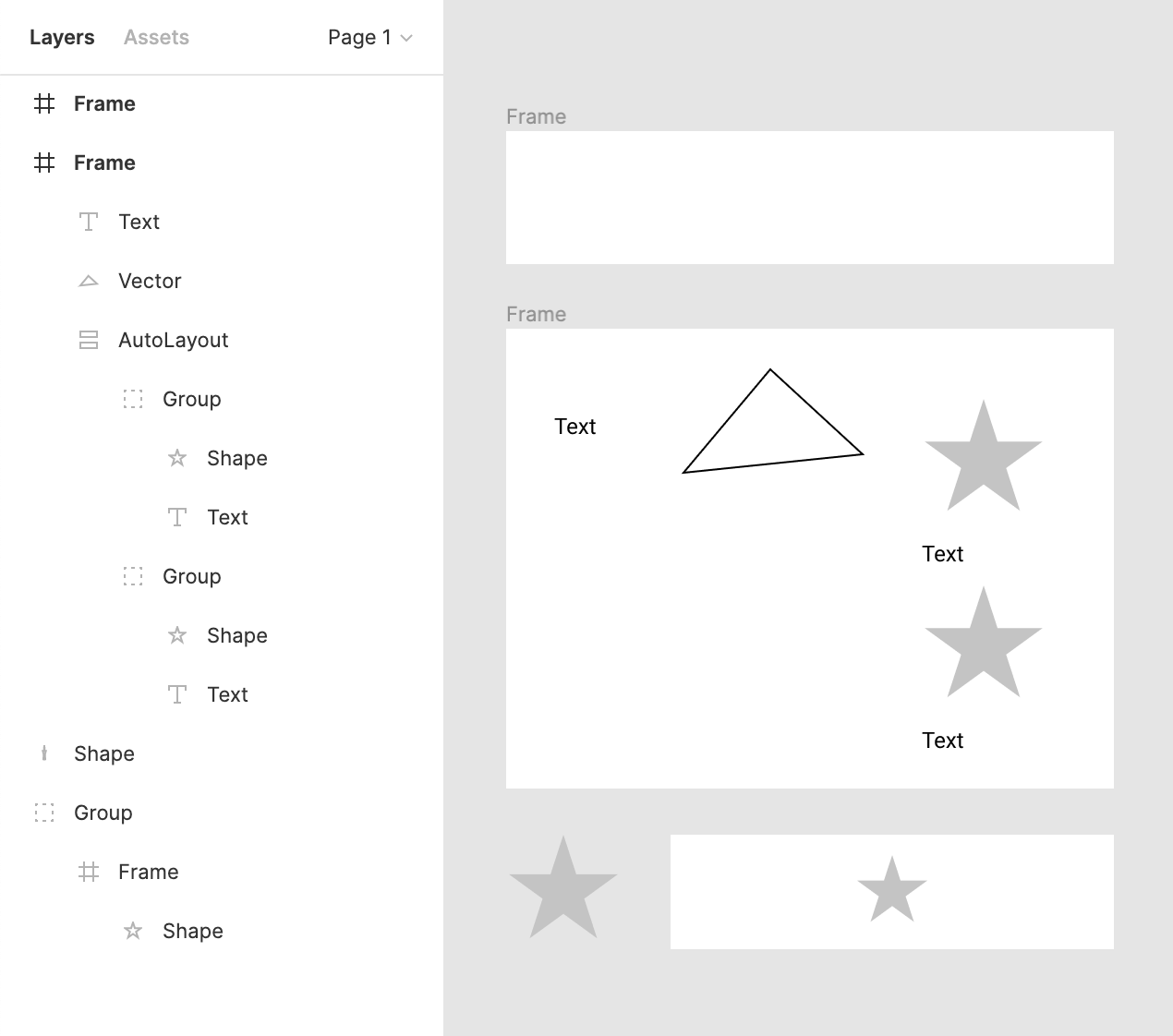
Using a node cluster we can model that image above as the following trees.
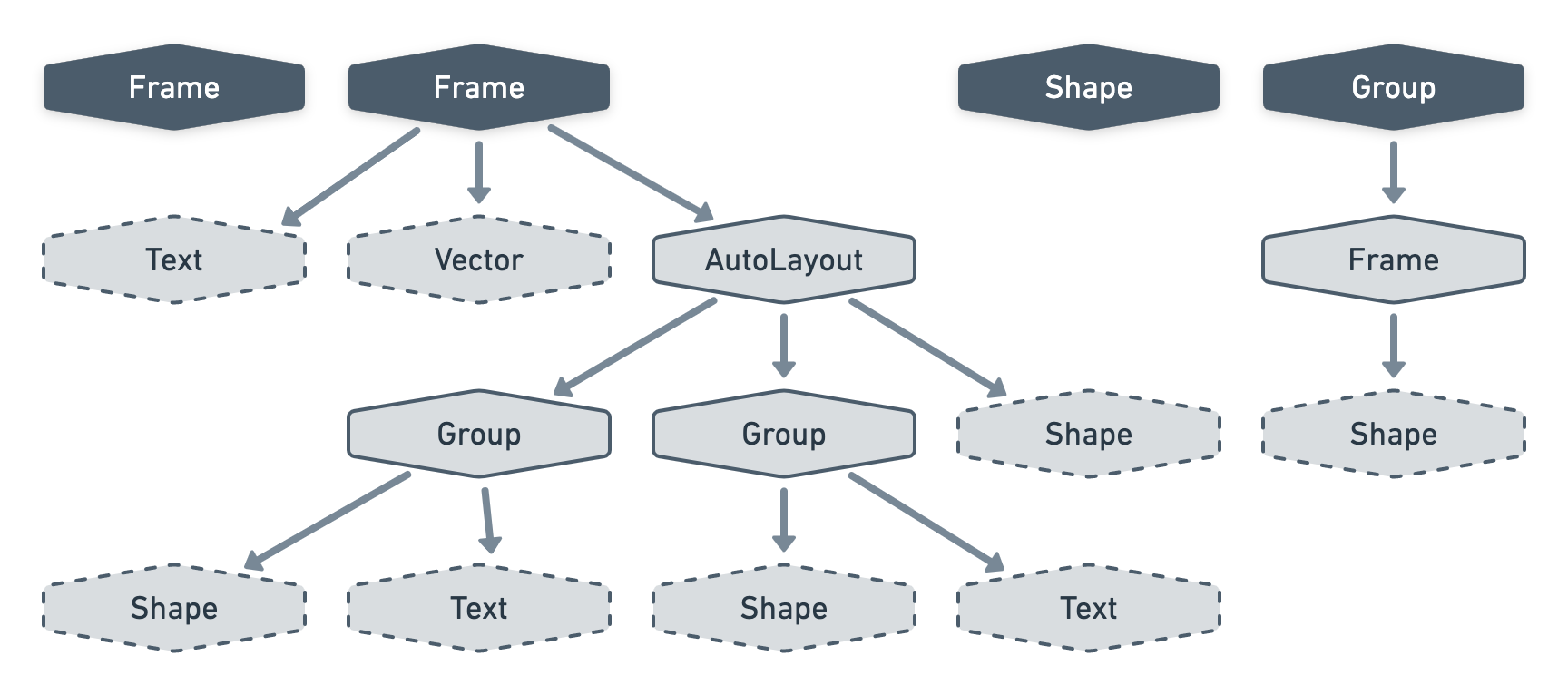
Since we’ll want our visitors to affect all the layers inside a project, let’s add yet another node type to transform our forest into one big tree — we'll call it ProjectTree.
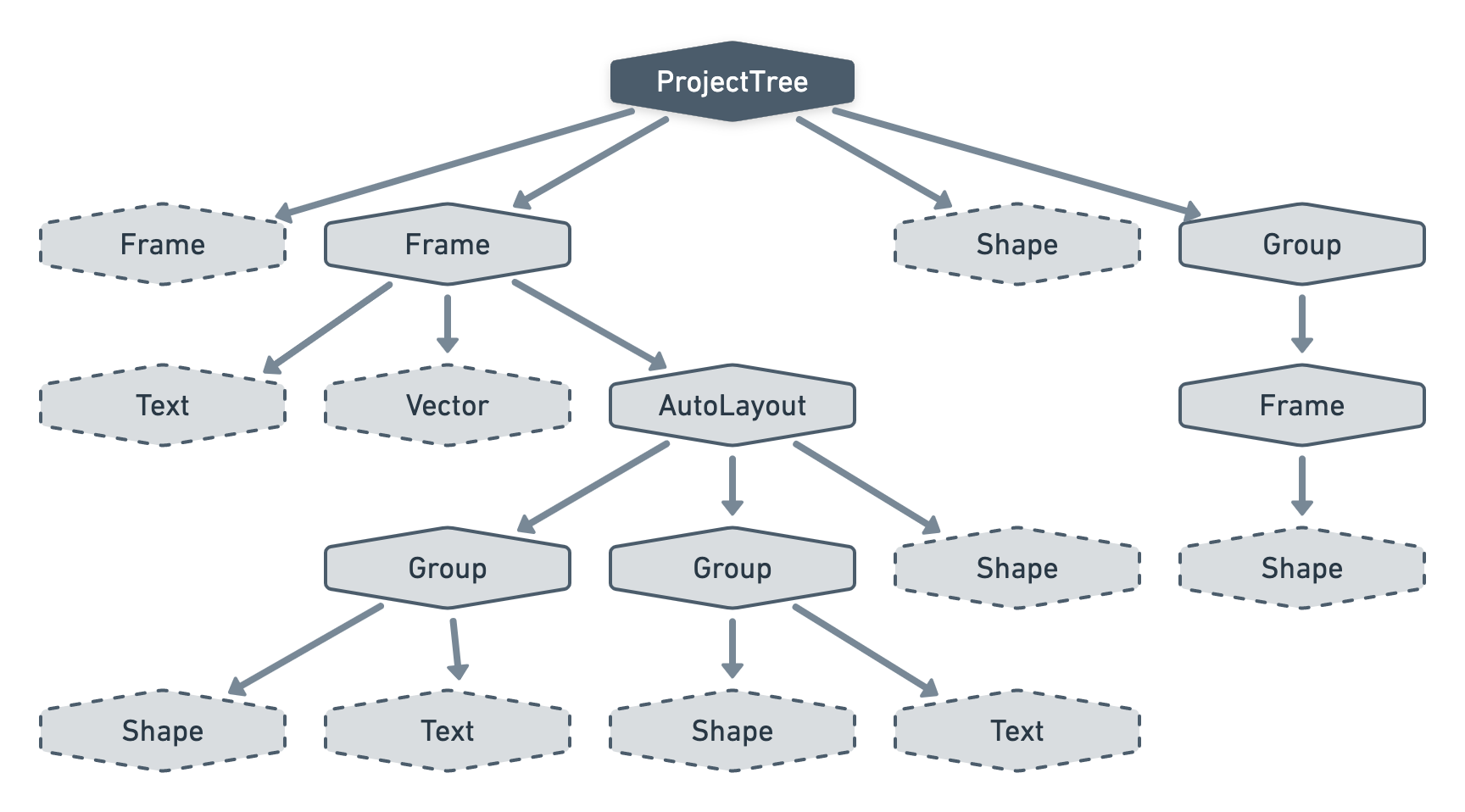
Okay, we’ve decided on how we want to model our tree. Now how do we want to store it? Should we create a new Eloquent model for each node type like we’ve done so far?
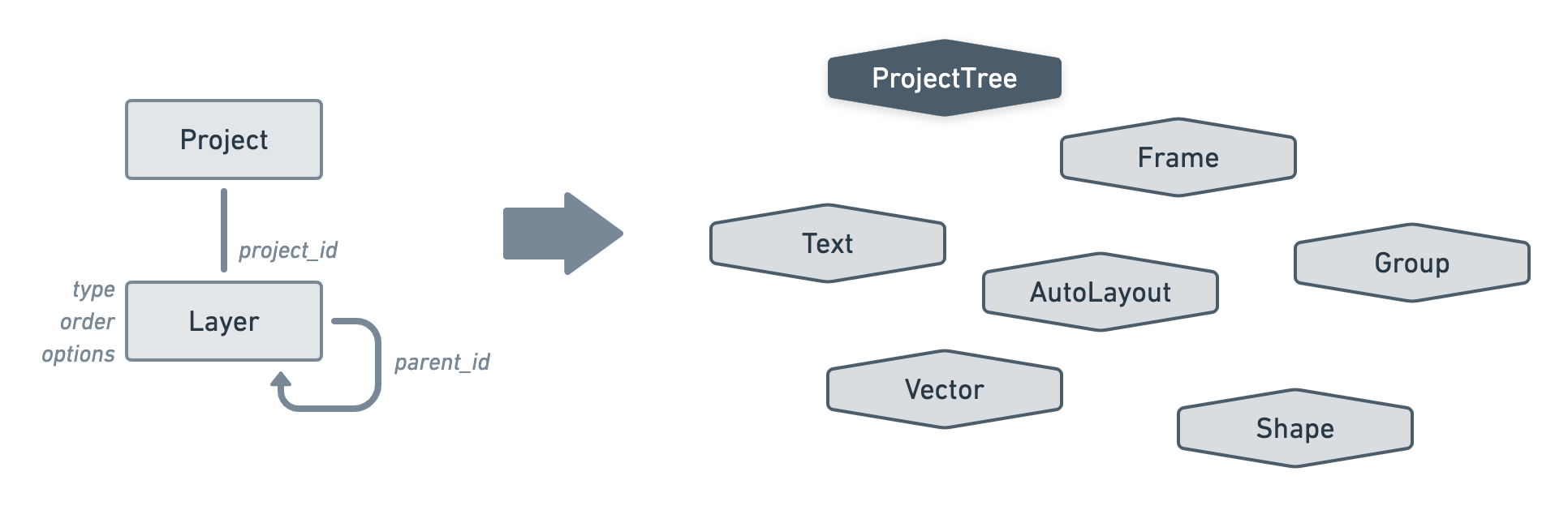
This could be tricky to normalise in a database since, for example, a Group model could have relationships with any of the other layer models. We will likely end up with a database schema full of polymorphic relationships and for what? Each type of layer follows a similar structure. They can all be named, have some fill options, some stroke options, some effects, some positioning, etc. Whilst our tree needs to distinguish the different types of layer, our database doesn’t require such information.
And so we’ve got our first example of a node cluster whose data representation differs from its database representation. This is not a rare situation to be in and, before blindly mapping our nodes as direct Eloquent models, we should take a step back and see if there isn’t a better way.
As a bonus, your node classes are now completely decoupled from the Eloquent active record and can now be simple Value Objects without any added complexity. For some people, that reason alone would be enough not to store nodes as Eloquent models. But you know, each to their own.
Back to the example at hand, we will store our node cluster using two Eloquent models. A Project and a Layer model with a one-to-many relationship between them. We will then model the recursion of our layers using a parent_id column as we’ve seen in the second category. Note that the performance warning I gave earlier still applies here.
To keep things simple, any data that is not shared between the different type of nodes will be stored in an options JSON column. Here is an example of a layers table and the node tree it represents.

Okay, let's start by creating our model classes and the relationships between them.
class Project extends Model
{
public function layers()
{
return $this->hasMany(Layer::class);
}
}
class Layer extends Model
{
public function parent()
{
return $this->belongsTo(static::class, 'parent_id');
}
public function children()
{
return $this->hasMany(static::class, 'parent_id');
}
}
Next, we need to implement the node classes which are now plain old PHP classes. As usual, we’ll create an interface for our nodes and an abstract class for our visitors.
interface FigmaVisitable
{
public function accept(FigmaVisitor $visitor);
}
abstract class FigmaVisitor
{
public function visitProjectTree(ProjectTree $projectTree);
public function visitFrame(Frame $frame);
public function visitGroup(Group $group);
public function visitAutoLayout(AutoLayout $autoLayout);
public function visitShape(Shape $shape);
public function visitVector(Vector $vector);
public function visitText(Text $text);
}
abstract class FigmaNode implements FigmaVisitable
{
//
}
class ProjectTree extends FigmaNode
{
public function __construct(
public array $children = []
) {}
public function accept(FigmaVisitor $visitor) {/* visitProjectTree */}
}
class Frame extends FigmaNode
{
public function __construct(
public array $children = []
) {}
public function accept(FigmaVisitor $visitor) {/* visitFrame */}
}
class Group extends FigmaNode
{
public function __construct(
public array $children = []
) {}
public function accept(FigmaVisitor $visitor) {/* visitGroup */}
}
class AutoLayout extends FigmaNode
{
public function __construct(
public array $children = [],
public array $margin = 0
) {}
public function accept(FigmaVisitor $visitor) {/* visitAutoLayout */}
}
class Shape extends FigmaNode
{
public function __construct(
public string $type,
public array $options = []
) {}
public function accept(FigmaVisitor $visitor) {/* visitShape */}
}
class Vector extends FigmaNode
{
public function __construct(
public array $vertices = [],
public array $edges = []
) {}
public function accept(FigmaVisitor $visitor) {/* visitVector */}
}
class Text extends FigmaNode
{
public function __construct(
public string $content,
public bool $uppercase = false
) {}
public function accept(FigmaVisitor $visitor) {/* visitText */}
}
Notice how we have full control on what data is expected from each node types even though, in our database, most of that data is stored in an options JSON column. That’s a nice way to focus on your cluster first and let the data mappers worry about how this is going to be stored and retrieved from the database.
Speaking of data mappers, we’ll need one that converts a Project Eloquent model into a ProjectTree node and one that persists a ProjectTree node as a Project Eloquent model.
For the former, we can implement a CreateProjectTree action class — which I would write using the Laravel Actions package but you do you 😅 — that goes through each layer of the project and recursively organise them as a tree.
For the latter, it’s a lot more fun since we now have a cluster of nodes that accepts visitors. Thus, we can create a PersistVisitor that takes care of that for us. We could either override the existing Project by synchronising all of its layers or we could create a brand new Project and archive the old one. That way, we can have a “history” mode where users can go back in time and revert their project to an old state if they want to.
Conclusion
Once we learn about a pattern in such details, it’s easy to get carried away and apply it everywhere. I know I do that a lot. Being excited about implementing something is great but it’s important to take the time to step back and ensure it’s the best approach for the matter at hand.
I hope this article gave you more insights on which use-cases could benefit from this pattern and which ones typically wouldn’t.
Remember the 2x2 matrix and keep in mind that without recursive node types, category 3 is more of a category 1.

We’re starting to reach the end of this series. As promised, the next and last episode will focus on handling node clusters that aren’t trees.
A dictionary of visitor operations

Dealing with non-trees
