And then there were nodes
If you’ve ever worked with me in the past, chances are you’ve seen me work with nodes and visitors. I may have a bit of a “law of the hammer” problem with that pattern but I love it too much to ignore it.
When appropriate, you simply organise your data in a big cluster of connected nodes and then you outsource operations to visitors that will independently visit your nodes in any way they see fit. Visitors can be used to access data, evaluate or infer new data from a cluster of nodes and even mutate the cluster itself. Visitors can then be chained one after the other to create more advanced systems.
Honestly, what is there not to love?
A teeny tiny bit of theory
Before we move on to more practical examples, let’s just make sure our terminology is aligned.
When talking about nodes connected to one another, I like to use the term cluster — or graph — since it’s vague enough to encompass any possible arrangements of nodes.
One of the most common types of clusters is the tree.
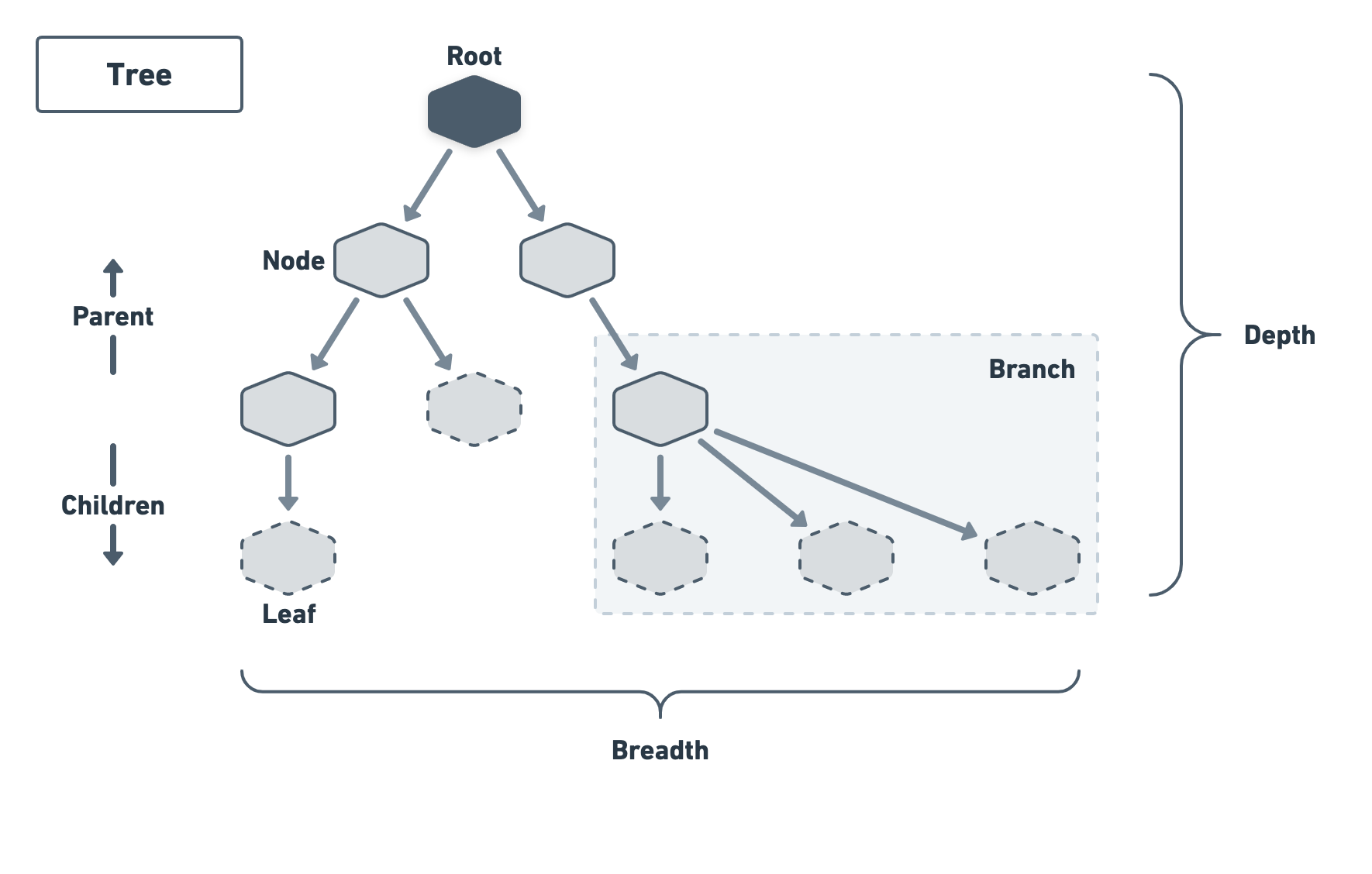
As per the analogy, it has exactly one root from which nodes recursively branch out, until we reach terminal nodes called leaves. The total number of leaves is called the breadth of the tree and the maximum level of recursion is called its depth.
Trees alone have many applications such as abstract syntax trees (AST) used to compile and evaluate languages — I will dedicate an entire series to them if you're interested.
However, it’s not uncommon to need a little more from your data structure.
For instance, you might end up with a collection of trees which is referred to as — drumrolls... — a forest. This can typically happen if you create a programming language composed of multiple statements evaluated one after the other.
However, when dealing with forests, it is common to create an additional node connecting all trees together to end up with one single tree.
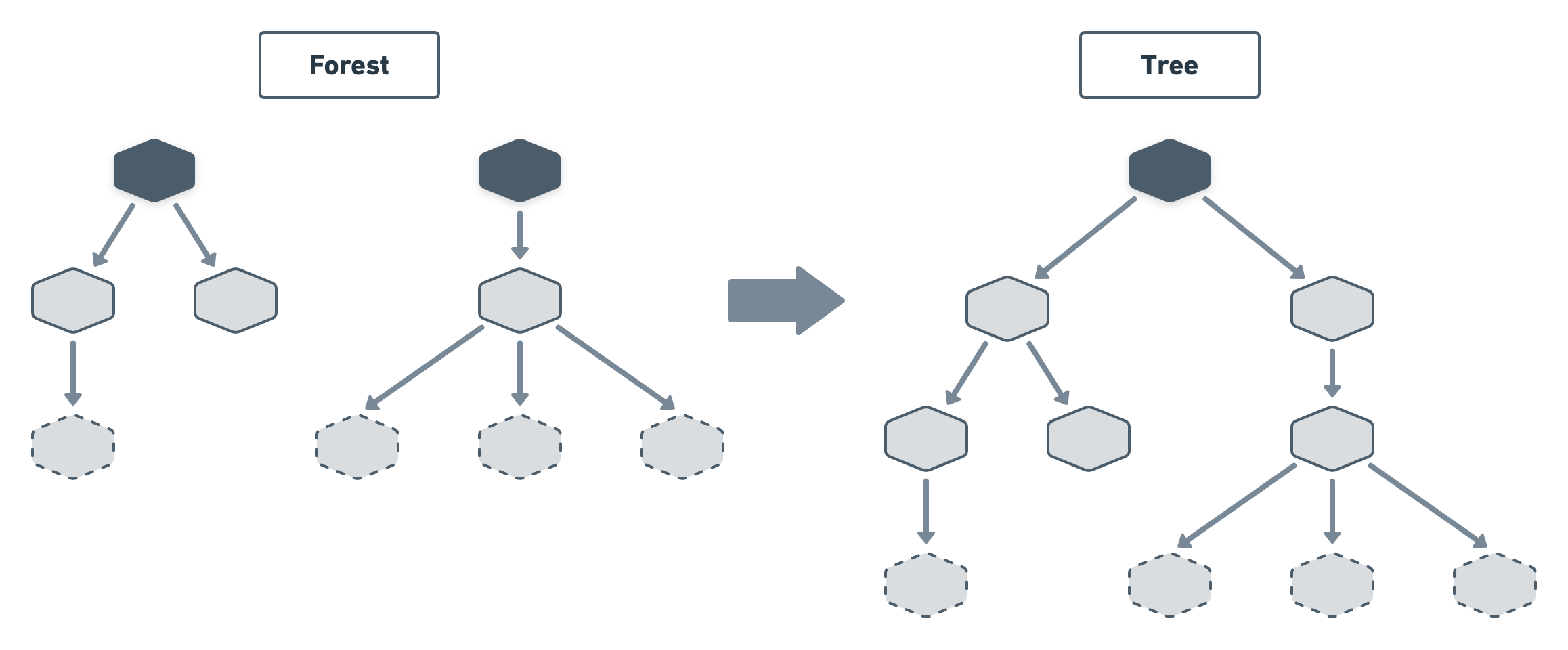
Having a single root makes it easier to use the Visitor pattern since, as we will see later, a visitor starts from one node and expand from there.
There are other scenarios that violate the tree structure you might want to consider when shaping your data as a cluster of nodes.
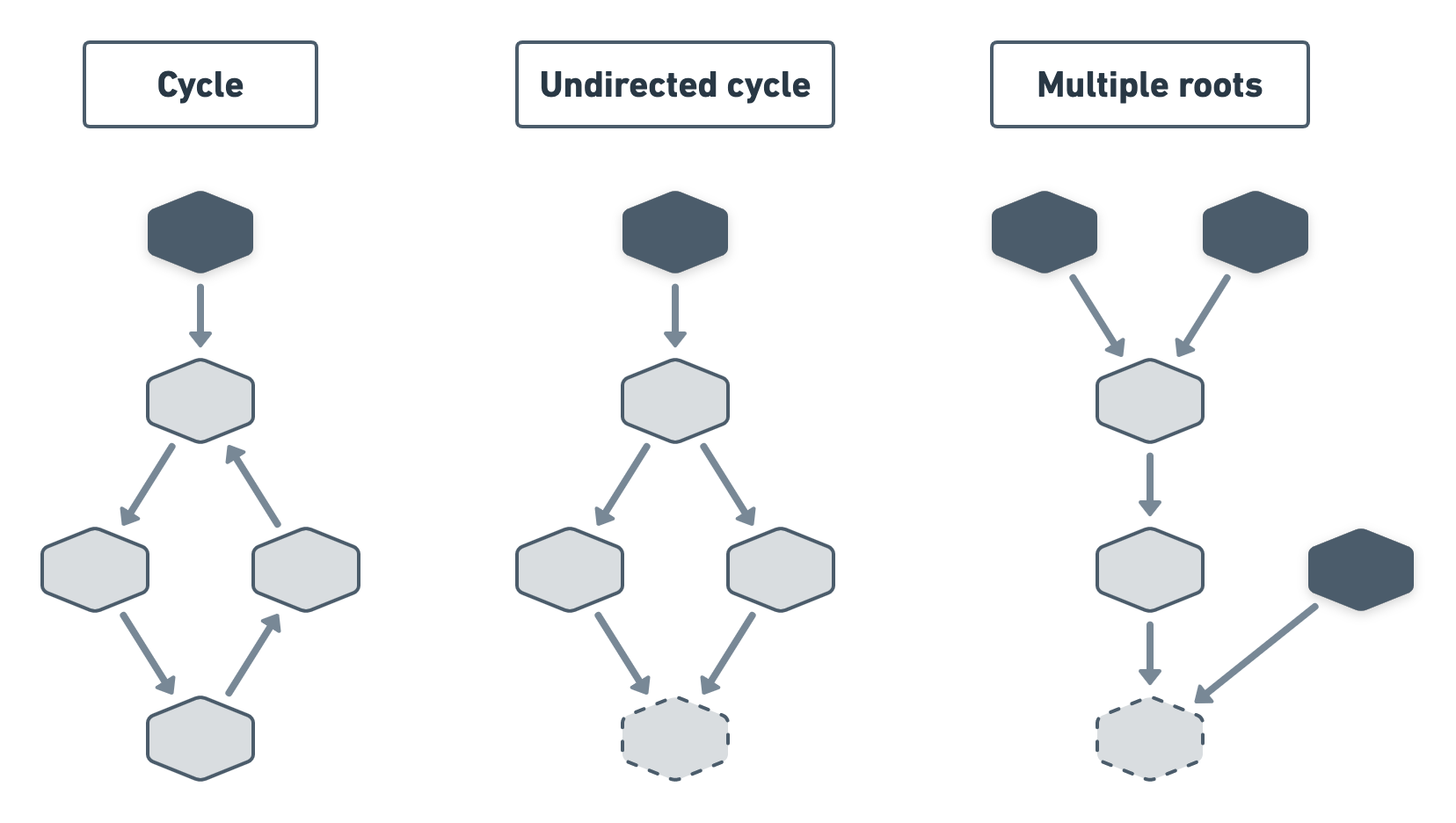
- Cycles. When a node ends up being the child of one of its descendants — its children or descendants of its children. Basically, there is a circular dependency in the cluster. We usually try to avoid this scenario since, if we’re not careful, we will end up in an infinite loop when visiting the cluster. Fortunately, there are ways to protect ourselves against them as we will see in this series.
- Undirected cycles. When a node has multiple parents — in a single-root cluster. It technically creates a circle but it’s directed in a way that won’t create infinite loops. However, it has the potential to make our visitors evaluate the same nodes multiples times and therefore can be fairly inefficient. Nothing a bit of caching can’t fix though.
- Multiple roots. We’ve talked about forests causing the “multiple root” problem but you may also end up with multiple roots within the same tree. This forces us to either decide on a single root to visit or run all the roots one by one potentially causing repetition issues. Again caching can help here and we can use the same solution for both the “undirected cycles” and “multiple roots” problems which we will also see in this series.
I recently had to work with a cluster of nodes that faced all of these challenges when creating webhook workflows.
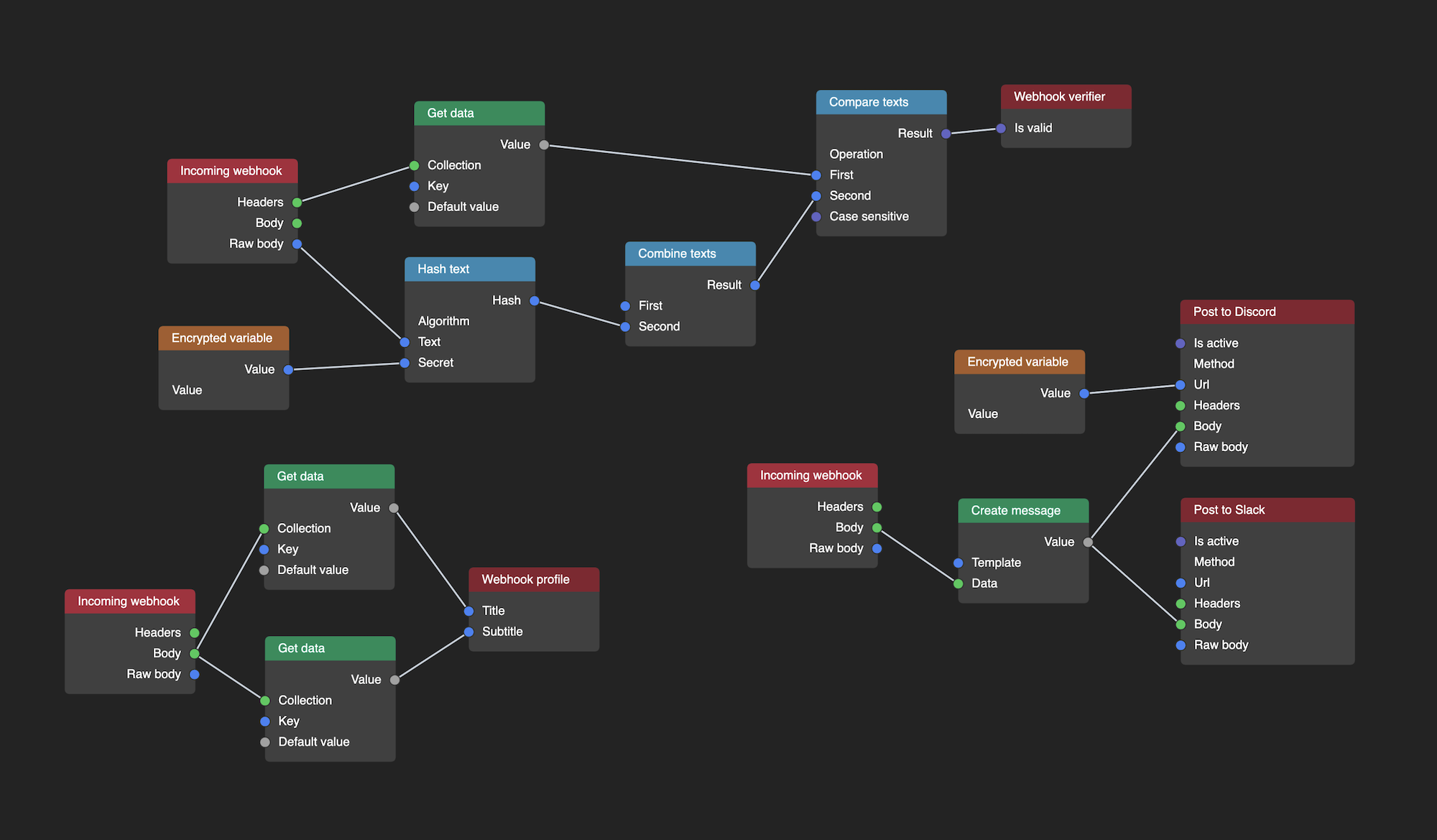
If you look closely, you will notice that:
- Nodes in the workflow may have multiple inputs and outputs (Undirected cycles).
- We may have many unconnected clusters (Forest).
- Each of these clusters may likely have more than one root (Multiple roots).
- Each of these clusters may end up forming a circular dependency (Cycles) — even though it is not the case in the image above.
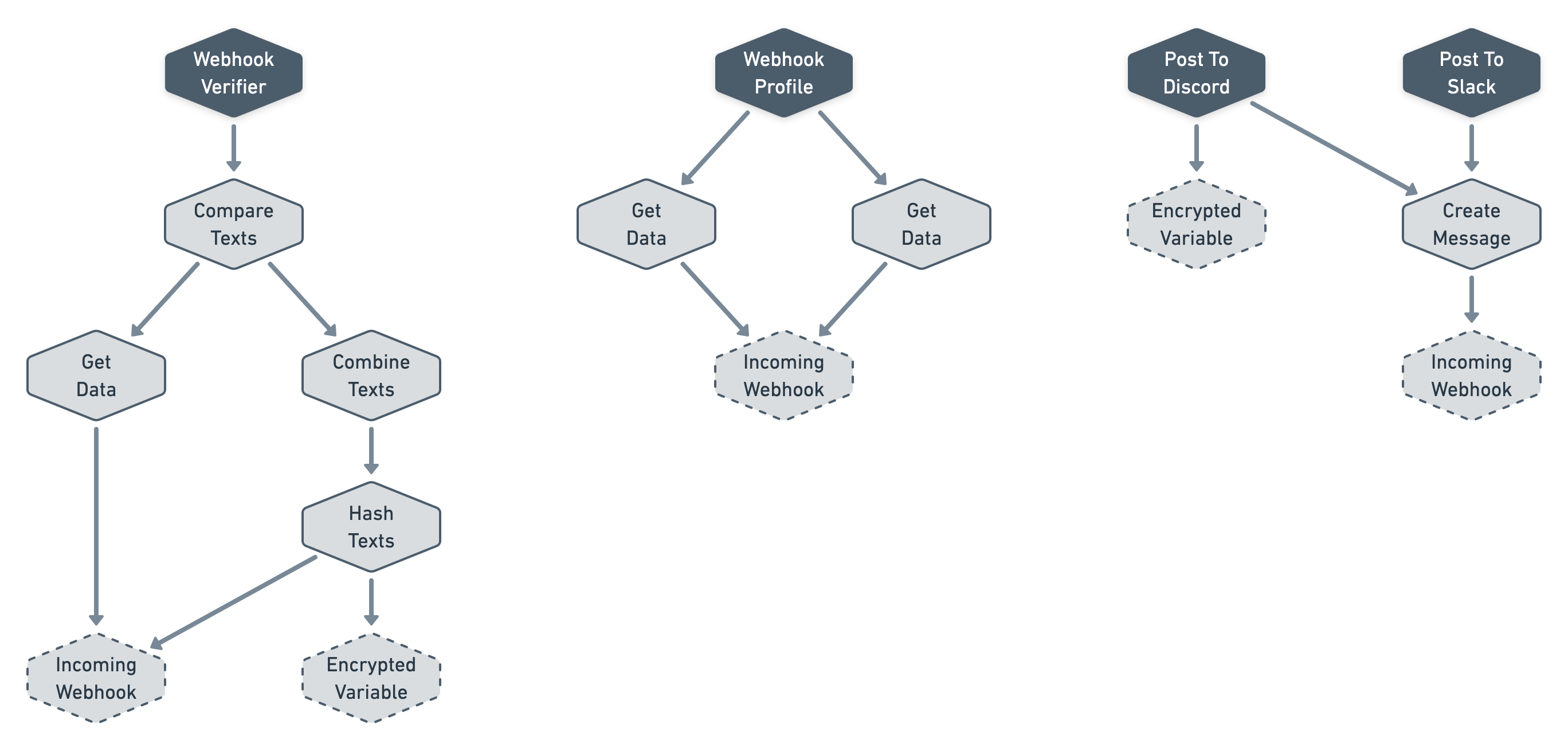
Notice how we use the final nodes as "roots" since that's what we are interested in evaluating in this use-case.
That being said, when organising your data as a cluster of nodes, you will likely end up needing a simple tree which is the best situation to be in. However, it’s good to know that this may not be enough and be prepared for it. For the rest of this series, we will focus on trees to keep things simple but I will dedicate an entire episode to tackle the circular dependency and caching problems we've just seen.
The calculator that remembers
Since it sounds like we're going to be talking a lot about nodes, let's come up with a simple yet thorough example we can reuse throughout this series.
Let's implement a simple calculator that can only add, Subtract and reverse the sign of numbers. To make it a little bit more spicy and interesting let's give the calculator a memory by adding the ability to assign a value to a variable and to retrieve that value at a later stage.
Thus, it looks like we need to implement the following nodes:
- Number. A node that simply contains the value of a number.
- Add. A node that requires two children and adds their values.
- Subtract. A node that requires two children and Subtracts their values.
- Minus. A node that requires one child and reverses the sign of its value.
- Assign. A node that requires one child and stores its value in a named variable.
- Get. A node that accesses the value of a previously assigned variable by name.
Let's take a look at an example using all these nodes.
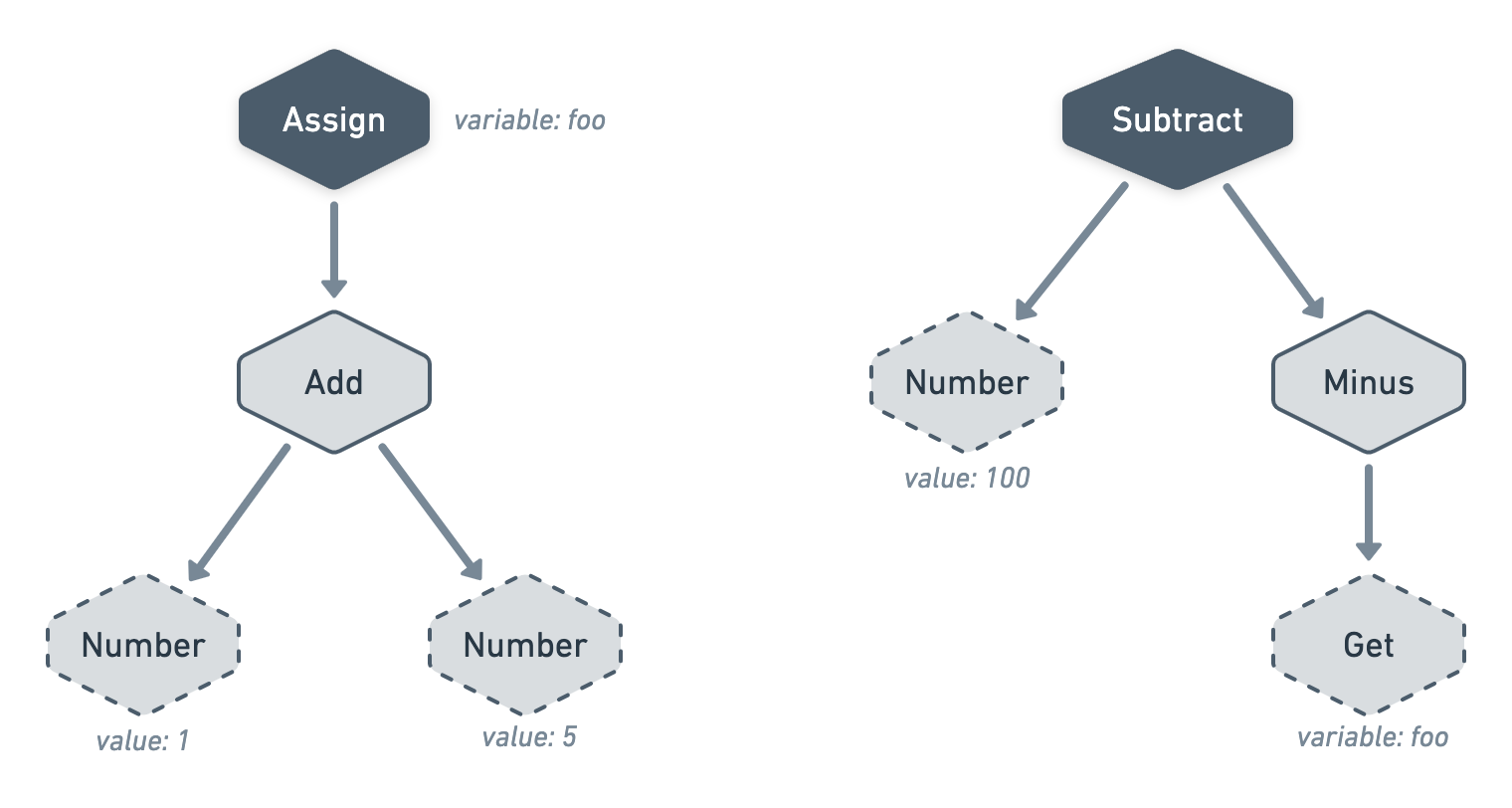
If we had to write that example using PHP, it would look like this:
$foo = 1 + 5;
100 - (- $foo);
As you can see, we've got ourselves a cluster of nodes with multiple disconnected trees — i.e. a forest. This is simply because our quirky calculator supports multiple statements. To fix this, let's add one more node that will act as a bearer of all statements:
- Calculator. A node that requires one or more children actings as statements.
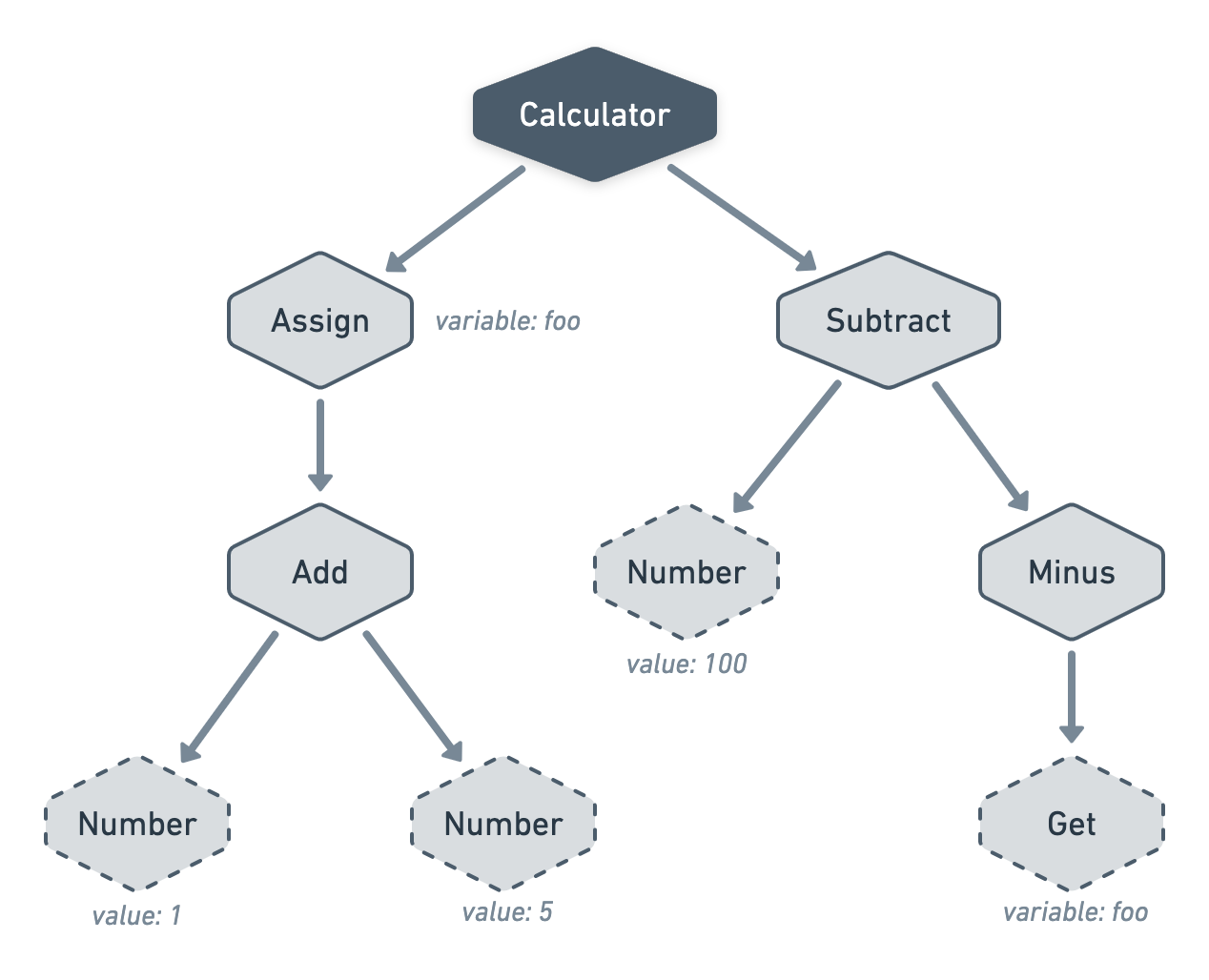
Note that we could have used a Scope node instead that keeps track of its own assignments and support nested scopes but let's not make things more complicated for ourselves.
Let's code!
Enough chitchat, let's get our hands dirty and code this tree.
We'll use public properties to keep things simple and make all our nodes extend a common abstract class.
abstract class Node {}
class Number extends Node {
public function __construct(public float $value){}
}
class Add extends Node {
public function __construct(public Node $left, public Node $right){}
}
class Subtract extends Node {
public function __construct(public Node $left, public Node $right){}
}
class Minus extends Node {
public function __construct(public Node $node){}
}
class Assign extends Node {
public function __construct(public string $variable, public Node $node){}
}
class Get extends Node {
public function __construct(public string $variable){}
}
class Calculator extends Node {
public function __construct(public array $statements){}
}
Now to re-create the tree in the previous example, we simply need to instantiate these classes like so:
$firstStatement = new Assign('foo', new Add(new Number(1), new Number(5)));
$secondStatement = new Subtract(new Number(100), new Minus(new Get('foo')));
$calculator = new Calculator([$firstStatement, $secondStatement]);
And voilà! We've got ourselves a tree. Now, let's do interesting things with it.
Unless stated otherwise, we'll use this particular tree throughout the series as it is versatile enough to be applied to a lot of different concepts.
We're now ready to tackle the Visitor pattern which we will see in the next episode!
Conclusion
Even though this article contains a lot of information, you might have noticed that some topics have been left aside. To avoid any confusion, let's have a quick look at what we will talk about in this series:
- How we can create operations on our clusters via visitors.
- How we can alter the way visitors go through our cluster.
- How to use nodes in real-life examples that are not programming languages.
- How to persists our nodes in a database.
- How to deal with circular dependencies and caching when visiting nodes.
That should give you enough insights to add nodes and visitors to your developer's toolbelt and/or to be more prepared when dealing with nodes.
In a follow-up series, I will go one step further and talk about how to create your own language from scratch using lexers, parsers, ASTs and visitors.
I hope you enjoy this series and I will see you in the next episode. 💪
The Visitor pattern