On modules and separation of concerns
Ah modules! That land of hope where software complexity is tamed in a variety of smaller islands that have very little to do with one another yet together create this beautiful archipelago that is your application.
Well... not quite.
In reality, things are a bit more messy than that. You code exists at different levels of abstraction as well as different levels of classification and finding the right separation of concern is A) time consuming B) full of compromises and C) only valid for the current state of your application.
Nevertheless, we developers love to talk about how to best organise our software architecture — and let’s be honest by that I mean “folder structure” — secretly hoping that one day we’ll find the holy grail of all folder structures and apply it to all our side projects.
At the risk of disappointing you, this article is not about presenting you with my version of such holy grail because I don’t believe it exists nor should exists. Instead, I will go through some key concepts that should hopefully help you make your own decisions when organising your code based on the cards you’re currently holding.
The application and you
There’s one point we should get out of the way immediately. Why should you care about this separation of concern and — more importantly — how far should you reasonably allow yourself to care about it?
Allow me to answer by providing more questions. What is your relationship with this application? Are you building this for a client? If so, what is the client’s relationship with this application and how much are they willing to pay you? Are you simply maintaining a legacy codebase for work and would like to reduce its technical debt? Are you creating a new side project and want to ship something quickly to make sure you’re not waisting your time?
Your answer to these questions plays an important role in how you should tackle the “separation of concern” problem or if you should at all. If you are building an application with an ambitious predefined scoped then you might benefit from tackling this problem from day one. If you’re refactoring a legacy codebase, the assessment of whether it should be done or not at this moment in time is even more important as you are left with a large technical debt to pay off. On the other hand, if you’re creating yet another side project without really knowing if others will see value in it, then you likely have better things to worry about than bloody separation of concerns. With any luck you will have to worry about it pretty quickly but this is what I call a “rich people’s problem”.
The illusion of stability
The average turnover time of a cell in your body is between 7 to 10 years. Whilst some cells last a lifetime, others are replaced every couple of days. Even though we think we are the same constant thing from birth to death, we are complex chemistry machineries whose internal structure is never final.
The same is true for any design system whose specifications are changing over time. Even if we were to structure the perfect separation of concerns for the current state of our application, it is an illusion to think that this structure will continue to be valid over time. Just as we are fluid things in constant change, so are our applications.
Moreover, no matter how adequate the current structure is, the less obvious it is understand, the more additional code will work against it.
The key point here is to remember that your job as a software architect — or “chaos killer” — is never over. Every little change in the code creates a new snapshot that requires a new internal balance. You can only do the best you can with the cards you have and adjust as and when the cards change.
Consistency over correctness
Even when focusing on the current state of your application, there is an infinite number of ways we can shape it. Whilst some of them are widely accepted as better than others, we are still left with a (smaller) infinite amount of "Right Ways".
As your application evolves, so do these "Right Ways" and the technology that supports them. This makes it even more difficult to keep the internal balance of the application and is the reason why we just want to rebuild the bloody thing every now and again.
Let’s take a look at a simple example. Imagine an application at a time t1 that defines all their routes in a big routes/web.php file. At the time, this was the most intuitive way to register your routes.
At time t2, you’ve introduced some modules to your application. All your models, controllers, jobs, etc. are now grouped by modules such as "Authentication", "Billing", etc.
At time t3, you’re implementing a new "TeamManagement" module to offer a new "Enterprise" billing plan. This new module comes with a lot of routes and, at this point, you’re already concerned by the size of your routes/web.php file. Additionally, the latest (hypothetical) version of Laravel comes with a brand new routing system that registers routes within special RouteRegistry classes. Excited about this new "Right Way" you decide to create a TeamManagamentRouteRegistry within your new module and everything feels much cleaner.
You are now left with two routing systems within your application. What is this I hear? Absolutely, the "Right Thing To Do" would be to refactor the good old routes/web.php file into the many RouteRegistry classes. However, in practice it’s not always that simple. What about that route that does not fit any module? What about these 50 routes that were created 2 years ago for a legacy API that will hopefully be retired soon anyway? What about that old package we rely on that requires us to run ThatOldPackage::routes();?
This is a quite a blatant example but a lot of decisions we make on a daily basis are much more discrete than that. Are we suddenly using ->whereName(…) instead of ->where('name', '=', …)? Are we starting to use Facades over dependency injections? Are we using the Http facade directly instead of creating one client for each third-party service? Are we now using commands to populate our staging environment on top of the initial seeders we wrote a while ago?
The point is this: The larger your application becomes, the more likely you will find different "Right Ways" which have evolved from a common ancestor and will likely mutate into more "Right Ways" in the future. And, unfortunately, many different "Right Ways" of achieving the same thing creates confusion within the system, destabilises the internal balance of your application and raises your technical debt.
If you don’t have the time or the resources to switch from one "Right Way" to another, it might be beneficial to stick to the current implementation and choose consistency over correctness. Yes, this will create a different kind of technical debt — e.g. a much bigger routes/web.php file — but one that is predicable and can be more easily refactored in the future.
To quote our good friend Saul Goodman: "Perfect is the enemy of perfectly adequate".
On cohesion and coupling
These two fancy words are just here to describe the interactions between the various elements that form your application. If these interactions are within the same module — or simply folder — they are called Cohesion (the good guys), if these interactions span multiple modules they are called Coupling (the bad guys).
For example, consider the following Laravel application with Controllers, models, jobs, etc. and the interactions between them.
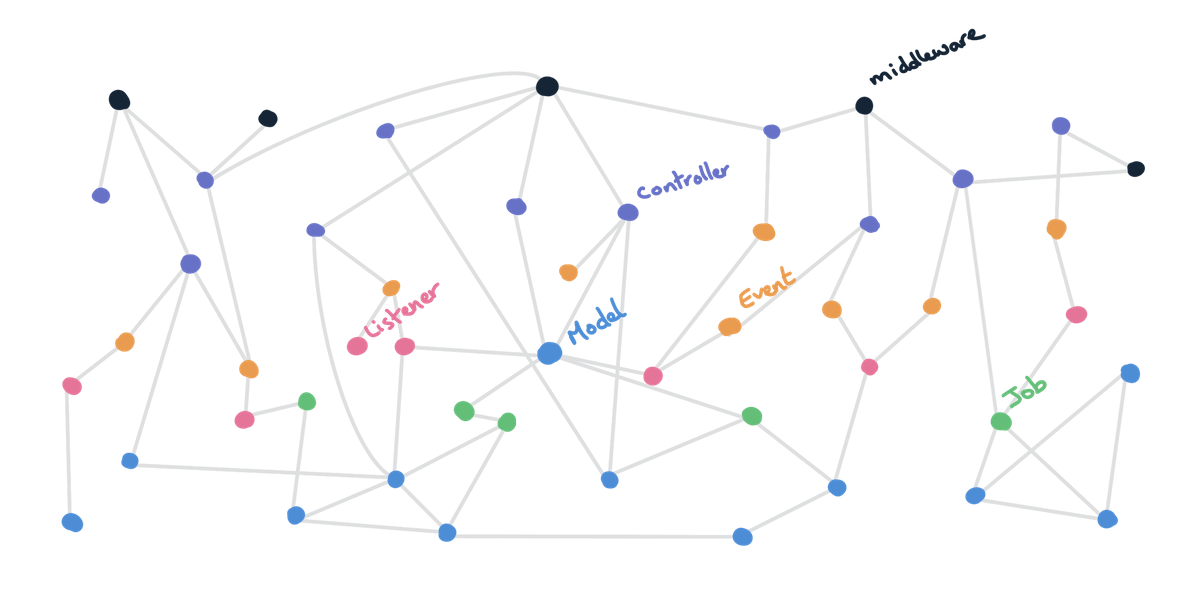
By default, Laravel separates everything by software patterns. This usually means a low cohesion (since classes of the same pattern don’t tend to interact with each other very much) and high coupling (since classes of different patterns tend to interact a lot together).
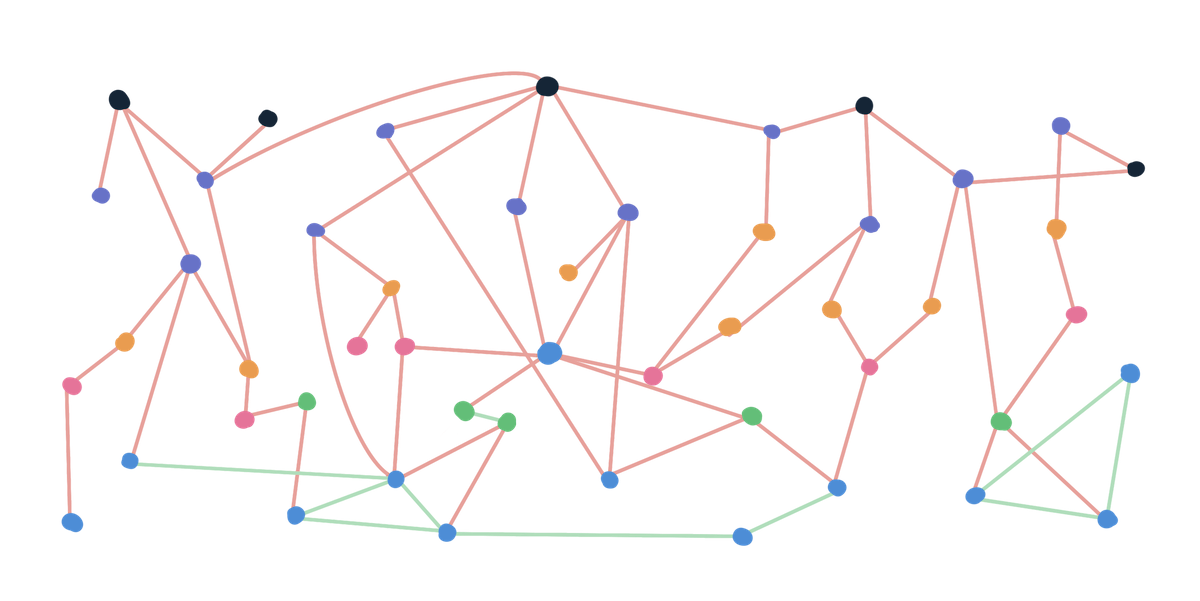
On the other hand, an application that groups everything by modules as the freedom of choosing modules that maximises cohesion and minimise coupling.
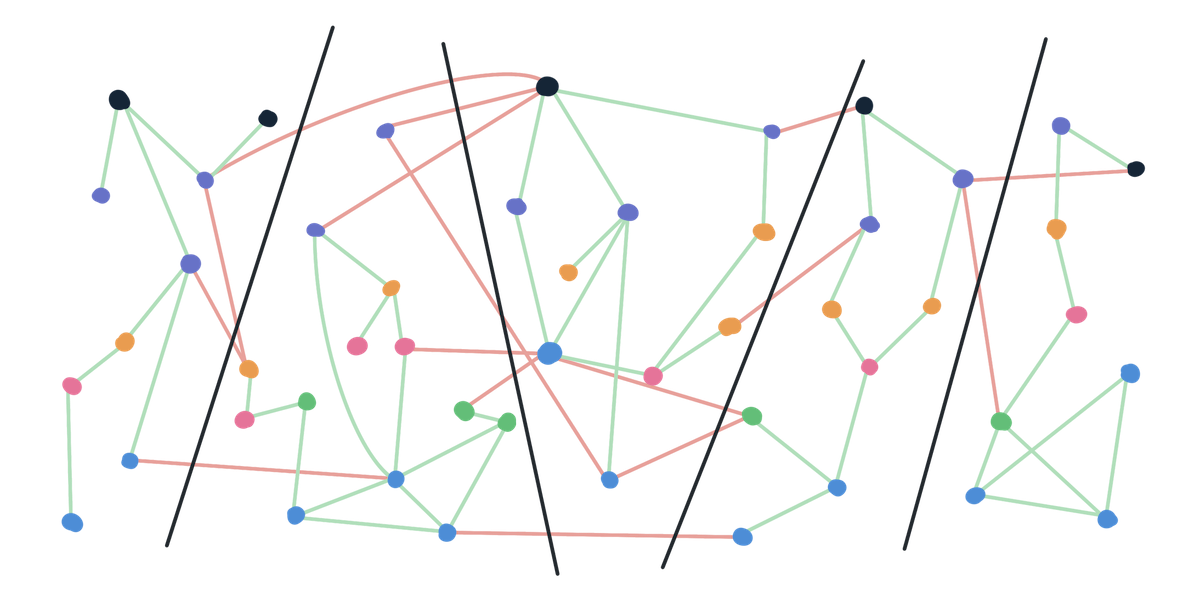
However, that doesn’t necessarily mean that the default Laravel structure never works. In fact, it does work pretty well at a whole different level: it is predictable. Introducing modules will inevitably depend on the current state of your application whereas, the default Laravel patterns will always be the same across all your projects and across their entire lifespan. One might argue that having hundreds of classes in your Controllers folder that all take care of different matters is bad practice but the value in having a consistent folder that contains all your controllers in one place is also non-negligible.
In short, both options are valid. Modules brings similar elements together but requires us to regularly reassess these boundaries as our application evolves. Additionally, predictability is no longer given and we’ve got to work on it ourselves.
Predictable modules
Consistency and common sense are key factors to keep modules predictable.
The goal here is to create a structure that any new developers can instantaneously and intuitively get their head around. Not because you’re going to need to hire developers or because you want to streamline the onboarding process — although you get that for free — but because anything other than that will:
- Increase the time you spend searching your own codebase
- Blur the boundaries of your modules making it even harder to decide where to write additional features.
- Make other developers — including your future self — work against the system to get the job done.
A widely accepted approach to structure your module is of course to follow your domain knowledge. This is the intuition most developers will have when they are introduced to your product and the value it provides to its customers. If by doing that, your modules have a low cohesion and a high coupling then perhaps your domain knowledge as changes since the beginning of your application and it might be time for a refactoring anyway.
Last but not least, your folder structure should have exactly the same depth on every single module. This is important to make modules predictable and familiar as they will all follow the same kind of structure.
Technically speaking, we want the equivalent of a full and complete binary tree. That way, no piece of code is ever deeper than X clicks away, where X is the depth of your full and complete folder structure.
It forces you to stay predictable and design a better separation of concerns between modules as the application evolves. For example, if a new ecosystem arises from the “Billing” module which enables the application to integrate with your accounting software, it might be a good idea to refactor it into its own “Accounting” module.
This is the reason why the Johnny.Decimal system “forbids” you to create additional folders once you reach an “ID” folder (the leaves of the tree).
This means that you’ll never get lost in layers upon layers of folders. It also makes you create quite specific folders for each thing, ensuring that you can always find what you want.
Final words
Just like us, our applications are evolving systems creating entropy every chance they get. Unlike us, however, they lack the ability to achieve homeostasis and thus we have to endure that task for them.
We have to rise above our own human flaws and provide the adequate discipline and consistency they deserve.
We are artisans after all.
